Steve Huffman是Reddit的共同创始人,最近他做了一次有趣的演示(视频,幻灯片,讲解实录),讲解他在把Reddit带到目前规模的过程中学到的7件事。Reddit依靠部署在Amazon EC2云上的超过20个数据库节点支撑,每月拥有超过750万用户和2亿7500万次点击,大概相当于每秒100个请求,这似乎不是一个很炫目的数字,但基于以下两点,我认为他的经验还是很有意义的:1. 由于Reddit的应用特点,所有页面都是动态处理的;2. 这个规模的并发压力覆盖了绝大多数初创在线服务能达到的水平,如果你的生意越过了这个水平线,基本上你的团队早知道该怎么做了。
同时,这里也没有令人大吃一惊的、魔幻的技巧,Steve只是告诉我们实际发生过的问题,以及确认有效的解决方案或者思路,我称之为“凡人可以掌握的技术”,不是咨询公司喜欢卖的“屠龙术”。
一共有七点,我会跟据我的理解加以说明,需要精确了解原始信息的朋友请参考本文开始提供的链接。这七点分别是:1. Crash Often 准备好应付经常性崩溃;2. Separation of Services 服务分离;3. Open Schema 开放式数据模型;4. Keep it Stateless 保持无状态;5. Memcache 内存缓存;6. Store Redundant Data 使用冗余数据;7. Work Offline 离线/异步工作。
在开始之前需要说明一点,每个应用都有自己的特定环境,连技术团队的风格都会影响解决方案的选择,在Reddit合用的方案未必适合其它团队,所以我觉得Reddit的这些经验更多的是启发思考,而不是鼓励照搬。我自己得到的最大启发是:用户体验比技术实现重要无数倍;没有美丽或丑陋的技术,只有合用和不合用的技术。好,下面开始。
第一课: 准备好应付经常性崩溃
要点:自动重启那些死掉的或者濒死的服务
当你的服务上线之后,维护成为一个大麻烦,不知道什么时候一个电话来你就必须立刻打开电脑连上服务器(如果还连得上)排错和恢复系统运行,无论是半夜睡觉的时候还是在国外的海滩度假的时候,相信我,这很容易让人崩溃。
一个能够自动重启死掉或者半死进程的方案能有效的缓解这种令人崩溃的状况,Reddit使用Supervise来自动重启应用,使用特制的守护进程来监控那些有问题的进程,比如占用内存和CPU过高,或者不能正常响应请求的,出现问题自动重启它们,这样整个系统可以继续接受用户请求。当然事后还是需要仔细研读日志找出问题根源,但至少可以在正常的时间去做,而不用把自己逼疯掉。
第二课: 服务分离
要点:把相似的进程和数据分组装箱
在一个服务器上干很多不同的事情会导致频繁的上下文切换,如果将不同的数据分离到不同的节点处理,就意味着索引可以一直高效的驻留内存,而不需要经常的进行交换。所以尽可能把相似(相关)的东西放在一起处理。另外,不要使用Python的threads,它们相对较慢,比较好的策略是使用分开的进程处理,比如spam处理、图片缩略图、查询缓存等服务,能分开的都分开,除了效率问题,这样的一大好处是可以随时将它们分离到单独的节点上处理。当然,这需要解决好进程间通信的问题,但是一旦解决了,整个架构就可以保持非常干净的状态,非常易于扩展。
第三课: 开放式数据模型
要点:别担心数据模型
开始的时候,Reddit的人就像绝大部分技术人员一样,很着紧他们的数据库,尽力保持数据模型的干净、漂亮、规范化。但后面的经验证明,其实完全不必担心数据库和数据模型,当规模上去之后,真正需要担心的是另一些问题,比如存储数据模型的改变和更新,往一个有着1000万条记录的表里增加一个列,会锁住整个表,甚至经常失败。最开始Reddit使用数据库复制来作备份和扩展,很快就认识到,这种架构下数据模型的更新和复制系统的维护都是超级痛苦的事情,曾经不得不时常重启复制系统而导致一整天在无数据备份的情况下运行(换句话说,这时候只要出现宕机之类的故障,肯定丢数据)。这种状态下应用升级部署会是巨大的麻烦,因为你要精妙的编排好应用和数据同时升级的流程。
Reddit随后转向了另外一种全然不同的数据模型风格,颇具教益。他们建立了一个Thing表和一个Data表;Reddit里的所有东西都是一个“Thing”:用户、分享链接、评论、子目录(subreddit,比如我们都经常看的proggit)、奖励分数等等,Thing表中维护所有这些东西的共通属性,例如“顶/踩”分数(up/down vote)、类型(说明这个Thing到底是哪种东西)、创建日期;而Data表中是这三个列:thing id、key、value,分别对应Thing的主键以及以键值对表述的属性。这样其实将关系模型中的属性转用行(通常情况下都是用列)来描述,每一行记录Thing的一个属性,比如这个Thing的titel、url、author、spam votes等等都是一行记录。这种数据模型几乎永远不需要改变,不需要增加数据表,不需要改变列结构,增加新的功能只需要增加数据行就行了,即使你要改变属性的名称、类型等,也只需要作数据Update操作即可,无论是开发还是部署、维护都变得简单很多。
当然,凡事有得必有失,要付出的代价就是,不能使用所有的关系能力了,你不能使用表关联(join),必须自己去维护数据的一致性——相对于之前描述的问题,这些其实反而是能够以较低代价解决的问题。另外,放弃表关联还有一个好处,你可以更容易的把数据分散到不同的节点上,不用担心主外键冲突这些麻烦事,比如需要把某些功能拆分出来用单独的机器处理时。最后事实证明,对于Reddit这类应用来说,这套机制运作的很好——后来他们就干脆迁移到NoSQL数据库Cassandra上了,关系型数据库不可动摇的时代已经过去了。。。
第四课:保持无状态
上面说的是数据模型和存储问题,这里则主要针对应用服务器,其目标是希望让每一个应用服务器节点都能够(在需要时)处理任何类型的请求。所谓的“状态”,完全可以理解为“在应用服务器上暂时保存的数据”,如果某台服务器上暂存了某些状态,那么相关的请求就被锁定在这个节点上而无法交由其它节点处理;如果一定要转移处理,就意味着要在所有应用服务器节点之间同步这些状态信息,Reddit确实有段时间是这么干的,但是这个方案有几个问题,一个是同步的工作内存占用很大,另一个是这种同步导致memcached的工作效率变差,所以后来他们重新改写了程序,移除了所有在应用服务器保存状态的代码,同时大量的使用memcached,这样当一个应用服务器节点挂了的时候,请求可以很快的在其它节点得到处理,代价最多是在那边重建少量的内存缓存而已,而这是自动的。这种模式也使增加新的节点更加容易。
第五课:内存缓存
要点:把一切都缓存起来
Reddit真的几乎把一切都扔进内存缓存了:数据库数据、会话(Session)数据、预渲染的页面、一些复杂计算的中间结果、预计算的列表和页面、用户权限、全局锁等等。据说在他们转向Cassandra之前,他们在MemcacheDB(这是一个类似memcached的服务,区别在于它的数据是持久化到硬盘的,其实也是一种NoSQL的实现,速度比传统RDBMS快很多)存储的数据多过PostgreSQL里的数据。
所有的查询都以相同的控制代码来处理,生成的结果在memcached中缓存;修改密码的链接和相关状态缓存20分钟,还有Captcha的处理也类似;对于所有不需要永久保存的都会用类似的限时模式来缓存。
他们在他们的应用框架里引入了记忆能力,所有计算结果都会缓存,包括标准化的页面、列表、其它几乎所有东西。
他们还利用内存缓存和过期(expiration)机制对所有东西实现了一种频率限制,这对付DOS类攻击相当有效。如果没有频率限制,一个恶意用户就能轻易的整垮系统。他们在缓存中保留了用户和爬虫的相关数据,如果用户的访问间隔低于一定标准——比如1秒——就会自动把请求顶回去,因为正常的用户是不可能点击这么快的;而一些合法的爬虫(比如Google crawler)是可以很快的访问的,所以这个频率限制是可调节的,当系统开始变慢,只要提高频率控制的阀值,很容易就可以过滤掉大部分这类请求,而保护起那些正常的浏览用户。
Reddit的应用框架把一切都看作列表,它的首页、用户收件箱、评论页面,都是列表。几乎所有这些都会通过预计算来生成并缓存。每一个分享链接的页面都自动的被预渲染,当然,为了更优化,可以和访问挂钩,那些刚被访问过的列表自动每隔30s重新预渲染和缓存一次。这样服务器节点的CPU能够被充分的利用,当系统开始变慢,只要增加缓存容量就行了。
另外他们还采用了一种机制,利用内存缓存来作为全局数据锁,以便应对在他们的系统中很容易发生的数据不一致风险,这个并不是一个最好的方案。我个人认为在这里他们的做法有一些潜在的问题,这可能在他们转向Cassandra之后有所改变,但是在这个介绍里并没有涉及引入Cassandra之后的情况。
第六课:使用冗余数据
要点:取得速度的关键是尽量预计算并缓存
要想建立一个超慢的网站,秘诀就是使用一个完美规范化的数据库,有请求来了就查询它,然后渲染页面,很快就能使每一次请求看上去都要很久很久才能响应。Reddit采用了相当极端的方式来改变这种状况,如果内容基本同样的数据会有不同的呈现方式,比如一组分享链接,在主页、在个人收件箱、在个人设定中,可能都需要有着细微差别的呈现,那么就把所有这些都预先生成好、分开存放,注意,这是在持久层做的。
举例来说,一个列表有15种不同的排序方式(热度、先新后旧、先旧后新、仅限本周、等等),当某个用户分享了一个链接,他们会重新计算所有可能被影响的列表,重新生成上述每种排序的列表版本,这确实会相当的浪费,但是浪费点资源比系统响应迟缓好得多,浪费磁盘和内存空间好过让用户等待。
第七课:离线/异步工作
要点:在后端做完必须的最少的工作,尽快地响应用户
如果需要做点什么费时的事情,别让用户等候,把它放进队列。例如用户在Reddit投票(vote)、更新用户Karma、以及其它很多事情,都可以异步处理,只要更新数据库告诉系统这个投票或者其它行为发生了,然后在队列里增加一个任务,让它去完成与此相关的所有事情,可能有几十个其它地方需要更新,但这些都不需要用户等着,等用户需要时,其他那些东西通常已经处理完毕并放进了缓存。
Reddit里典型的离线事务:1. 列表预计算 2. 缩略图预取 3. 作弊检查 4. 清理垃圾信息(spam) 5. 计算奖励分 6. 更新查询索引。这些事情都不需要让用户等待,全可以离线异步处理,Reddit充分利用用户浏览和其它时间来异步的处理,尽量不给用户体验带来不必要的延迟。下面是这种架构的示意图:
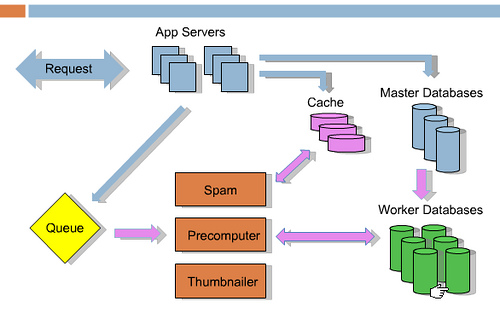
蓝色箭头表示当一个请求进来以后发生的事情,比如有人提交了一个分享链接或者一个投票,它会去到缓存、主数据库、任务队列,然后返回给用户,接下来的事情全都是离线事务,用粉红色箭头表示(用户感受不到的部分),包括垃圾信息处理、预计算、缩略图处理等从队列中弹出,分别处理,需要时还会更新数据库。Reddit采用RabbitMQ来做消息和任务队列管理。